【VLLM】vllm如何实现本地大模型部署
请注意,本文编写于 90 天前,最后修改于 85 天前,其中某些信息可能已经过时。
目录
手把手教你使用vllm本地部署大模型
一、环境准备
- 系统:Ununtu 22.04 LTS
- 显卡:3080TI
- 显卡驱动版本:580
- cuda版本:13.0
1、安装显卡驱动580
1.1、更新系统+安装依赖
展开代码sudo apt update && sudo apt upgrade -y sudo apt install -y gcc make linux-headers-$(uname-r)
1.2、禁用开源驱动 nouveau
展开代码sudo echo "blacklist nouveau" >> /etc/modprobe.d/blacklist-nouveau.conf sudo echo "options nouveau modeset=0" >> /etc/modprobe.d/blacklist-nouveau.conf #更新内核配置 sudo update-initramfs -u sudo reboot
验证是否禁用成功
展开代码lsmod | grep nouveau
1.3、安装驱动
展开代码sudo apt install -y nvidia-driver-580 sudo reboot
验证是否成功
展开代码nvidia-smi
成功可以看到输出
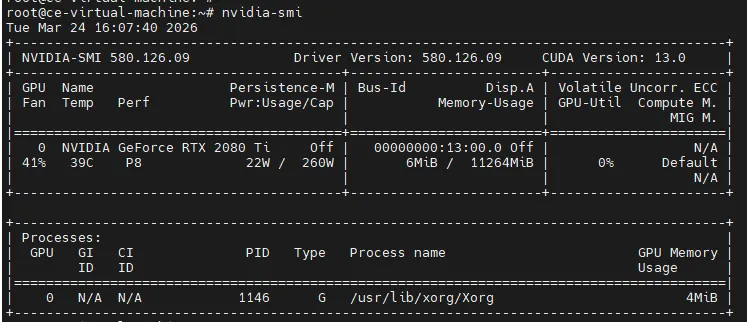
2、安装cuda
地址:https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/
2.1、添加官方源
展开代码wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb sudo dpkg -i cuda-keyring_1.1-1_all.deb sudo apt update
2.2、安装
展开代码sudo apt install -y cuda-13-0
2.3、配置环境变量
展开代码echo 'export PATH=/usr/local/cuda-13.0/bin:$PATH' >> ~/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc source ~/.bashrc
二、安装vllm
1、装docker
1.1、卸载旧的
展开代码sudo apt remove -y docker docker-engine docker.io containerd runc
1.2、安装依赖
展开代码sudo apt update sudo apt install -y ca-certificates curl gnupg lsb-release
1.3、添加 Docker 官方 GPG 密钥
展开代码sudo mkdir -p /etc/apt/keyrings #用阿里云的源 curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg sudo chmod a+r /etc/apt/keyrings/docker.gpg
1.4、添加Docker官方源
展开代码echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
1.5、安装docker引擎
展开代码sudo apt update sudo apt install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
1.5、开启自启动
展开代码sudo systemctl enable docker sudo systemctl start docker
2、安装nvdia-docker
这是让 Docker 容器调用 3080Ti 的核心组件,只装一次。
展开代码# 1. 安装密钥 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg # 或者下载下来使用如下命令 cat gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg # 2. 添加国内可用源 curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list #或者下载下来使用如下命令 cat nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # 3. 安装 nvidia-container-toolkit sudo apt update && sudo apt install -y nvidia-container-toolkit # 4. 配置 Docker sudo nvidia-ctk runtime configure --runtime=docker # 5. 重启 Docker 生效 sudo systemctl restart docker
验证是否安装成功
展开代码sudo docker run --rm --gpus all nvidia/cuda:12.1.1-base-ubuntu22.04 nvidia-smi
输出显卡信息则成功
3、安装vllm(docker)
3.1、拉镜像
展开代码docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/vllm/vllm-openai:v0.18.0-cu130 docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/vllm/vllm-openai:v0.18.0-cu130 vllm/vllm-openai:v0.18.0-cu130
3.2、编写docker-compose(实现宿主机模型映射到docker里面)
展开代码version: '3.8' services: vllm: image: vllm/vllm-openai:v0.4.2 container_name: vllm restart: always ipc: host network_mode: host ports: - "8000:8000" deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] volumes: # 左边 ↓ 你的宿主机模型路径(一定要改成你自己的) - /home/slark/vllm/models:/models environment: - HUGGINGFACE_HUB_CACHE=/models - PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:32,expandable_segments:True command: > --model /models/Qwen3.5-4B --trust-remote-code --dtype half --api-key 123456 --max-model-len 512 --gpu-memory-utilization 0.98 --enforce-eager
3.2、启动
展开代码docker compose up d docker compose logs -f
本文作者:刘涛
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录