目录
回顾一下这么多年Redis的使用经历,看看源码和底层原理。
一、八种数据结构
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:
- 简单动态字符串(SDS)
- LinkedList(双向链表)
- Dict/HashTable(哈希表/字典)
- SkipList(跳跃表)
- Intset(整数集合)
- ZipList(压缩列表)
- QuickList(快速列表)
- listpack
五种基本数据类型对应的底层数据结构实现如下:
| String | List | Hash | Set | ZSet |
|---|---|---|---|---|
| SDS | LinkedList/Zip List/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
1、SDS
数据结构如下:
展开代码struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; // 已使用字节数 uint8_t alloc; // 分配的总字节数 unsigned char flags;// 类型标记 char buf[]; // 实际存储的字节数组 };
SDS(Simple Dynamic Strings)是Redis中用于表示字符串的数据结构之一,它具有以下特点:
- 灵活性: SDS 可以存储字符串,也可以存储二进制数据,包括空字符,因此在处理二进制数据时更为灵活,不受空字符的限制。
- 缓存长度信息: SDS 在头部保存了字符串的长度信息,因此可以在 O(1) 的时间复杂度内获取字符串的长度,而不需要遍历整个字符串,提高了获取长度的效率。
- 动态扩容: SDS 可以根据实际存储的数据动态扩容,当字符串长度变长时,SDS 会自动进行内存的扩展,而不需要手动管理内存,提高了内存管理的便利性。
特点总结:二进制安全、O(1)复杂度获取长度、自动扩容机制
2、LinkedList
数据结构如下:
展开代码typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct list { listNode *head; listNode *tail; unsigned long len; // ...其他函数指针 } list;
Redis中的 List 就是⽤双端链表实现的,双端链表(Doubly Linked List)是一种链表数据结构,每个节点除了包含指向下一个节点的指针外,还包含指向上一个节点的指针,双端链表的链表节点可以保存不同类型的值,⽀持在两端进⾏元素的快速插⼊和删除,并且链表结构提供了表头指针和表尾指针,获取链表的表头节点和表尾节点的时间复杂度只需O(1);获取链表数量的时间复杂度也只需O(1)。
优点如下;
- 可以在头部和尾部高效地进行插入和删除操作,时间复杂度为 O(1)。
- 可以支持双向遍历,能够从头部和尾部同时进行遍历操作。
缺点如下:
- 链表每个节点之间的内存都是不连续的,意味着⽆法很好利⽤ CPU 缓存
- 保存⼀个链表节点的值都需要⼀个链表节点结构头的分配,内存开销较⼤。
双端链表常被用于需要频繁进行插入和删除操作,并且需要支持双向遍历的场景,比如实现队列、栈、LRU缓存等数据结构和算法
注:Redis3.2之前是用双向列表作为List的底层实现,之后是QuickList。
3、Dict/HashTable
数据结构如下:
展开代码typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; } v; struct dictEntry *next; } dictEntry; typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht;
哈希表(Hash Table)是一种用于存储键值对(key-value pairs)的数据结构,在 Redis 中被广泛应用于实现各种数据类型,如哈希表(Hashes)和集合(Sets)等。
在哈希表中,每个键都经过哈希函数处理后映射到一个唯一的索引位置,然后将对应的值存储在该位置上。这样,通过键可以快速定位到对应的值,实现了高效的查找操作。
HashTable本身数据结构定义为dictht,由dictEntry数组组成,dictEntry是一个单向链表的节点,代表hashtable种的一条记录,包含key、value以及指向下一个节点的指针(用于处理hash碰撞)
dictht size是hashtable种bucket的数量,sizemask是size的位掩码,用于计算对应的key应该存储在哪个bucket中(位运算的效率高于取模运算),而used存储的是是实际存储的记录的数量
Hash插入的过程: 1、先根据MurmurHash2算法计算除key的hash值 2、根绝sizemask和hash值进行与运算计算出index 3、遍历链表,如果有相同的key值则替换,没有的话则使用头插法(因为只存储了指向下一个节点的指针)
4、SkipList
数据结构如下:
展开代码typedef struct zskiplistNode { sds ele; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
跳跃表是⼀种在链表基础上改进过来的,实现了⼀种「多层」的有序链表,当数据量很⼤时,跳表的查找复杂度就 是O(logN)。在 Redis 中,有序集合(Sorted Set)就是通过跳表来实现的,因为跳表具有快速的查找和插入操作,非常适合用于实现有序集合类数据结构。
1、多层链表架构:
跳表由多层有序链表组成,最底层(Level 1)包含所有元素,上层每层均为下层的稀疏索引。例如,Level 2可能每隔两个节点抽取一个索引,Level 3每隔四个节点抽取一个索引,形成类似“金字塔”的结构。
2、节点随机层数:
每个节点的层数由随机算法决定(如Redis采用幂次定律),高层节点数量呈指数级减少。例如,50%节点在Level 1,25%在Level 2,以此类推。

跳表的查找过程如下:
- 查找⼀个跳表节点的过程时,跳表会从头节点的最⾼层开始,逐⼀遍历每⼀层。在遍历某⼀层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进⾏判断:
- 如果当前节点的权重⼩于要查找的权重时,跳表就会访问该层上的下⼀个节点。
- 如果当前节点的权重等于要查找的权重时,并且当前节点的 SDS 类型数据⼩于要查找的数据时,跳表就会访问该层上的下⼀个节点。
- 如果上⾯两个条件都不满⾜,或者下⼀个节点为空时,跳表就会使⽤⽬前遍历到的节点的 level 数组⾥的下⼀层指针,然后沿着下⼀层指针继续查找。
结合实例就是这样:
假设跳表包含元素[3,6,7,9,12,17,19,21,25,26,30,35],其层级分布为:
- Level 2: 3 → 12 → 25(顶层)
- Level 1: 3 → 7 → 12 → 19 → 25 → 30
- Level 0: 3 → 6 → 7 → 9 → 12 → 17 → 19 → 21 → 25 → 26 → 30 → 35(底层完整链表)
查询目标19的过程:
- 从顶层Level 2开始:比较第一个节点3,19>3,继续右移;下一个节点12,19>12,继续右移;遇到25时发现19<25,停止右移并下移到Level 1的12节点
- 在Level 1继续查找:从12出发,右移遇到19(19=目标值),查找成功。若未找到则继续下移到Level 0
若目标为15(不存在):
- Level 2: 3 → 12(15>12),下移到Level 1的12节点;
- Level 1: 12 → 19(15<19),下移到Level 0的12节点;
- Level 0: 12 → 17(15<17),确认不存在
跳表插入注意的点:
- 调用随机函数(如Redis的zslRandomLevel())生成层数;
- 从指定层数开始向下,如果找到节点小于当前值,则更新链表的前后指针的关系,插入,并继续遍历,直到0层
5、Intset(整数集合)
数据结构如下:
展开代码typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset;
整数集合(Integers Set)是 Redis 中的一种特殊数据结构,用于高效地存储整数值的集合。它是为了在存储一组整数时,提供更加紧凑和高效的存储方式而设计的。
主要特点包括:
- 紧凑存储:整数集合使用紧凑的数据结构存储整数值,不像普通的数组那样每个元素都需要占用固定的内存空间,而是根据整数的大小动态调整所需的存储空间,节省了内存的使用。
- 快速查找:由于整数集合中的元素是有序的,并且使用了特定的算法进行存储和查找,因此可以在 O(logN) 的时间复杂度内实现查找操作,其中 N 表示整数集合中的元素个数。
- 支持多种整数类型:整数集合可以存储多种整数类型,包括 int16、int32、int64 等,根据存储的整数值的大小自动选择合适的数据类型。
- 动态调整:整数集合在存储整数值的过程中,会根据需要动态调整存储空间,避免了固定大小数组可能带来的空间浪费或溢出问题。
6、QuickList
数据结构如下:
展开代码typedef struct quicklist { quicklistNode *head; quicklistNode *tail; unsigned long count; unsigned long len; int fill : 16; unsigned int compress : 16; } quicklist; typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *zl; unsigned int sz; unsigned int count : 16; unsigned int encoding : 2; unsigned int container : 2; unsigned int recompress : 1; } quicklistNode;
quicklist本质是双链表,里面所有的node分为两类,根据compress区分,如果coompress为0,则该节点存储的就是quicklistNode对象,否则,会类似ziplist一样,对quicklist进行LZF压缩(LZF是种无损压缩算法)。
那么问题来了,为什么不所有全压缩,而是部分压缩呢?
其实从统计而已,list两端的数据变更最为频繁,像lpush,rpush,lpop,rpop等命令都是在两端操作,如果频繁压缩或解压缩会代码不必要的性能损耗。从这里可以看出 redis其实并不是一味追求性能,它也在努力减少存储占用、在存储和性能之间做trade-off。
7、ZipList
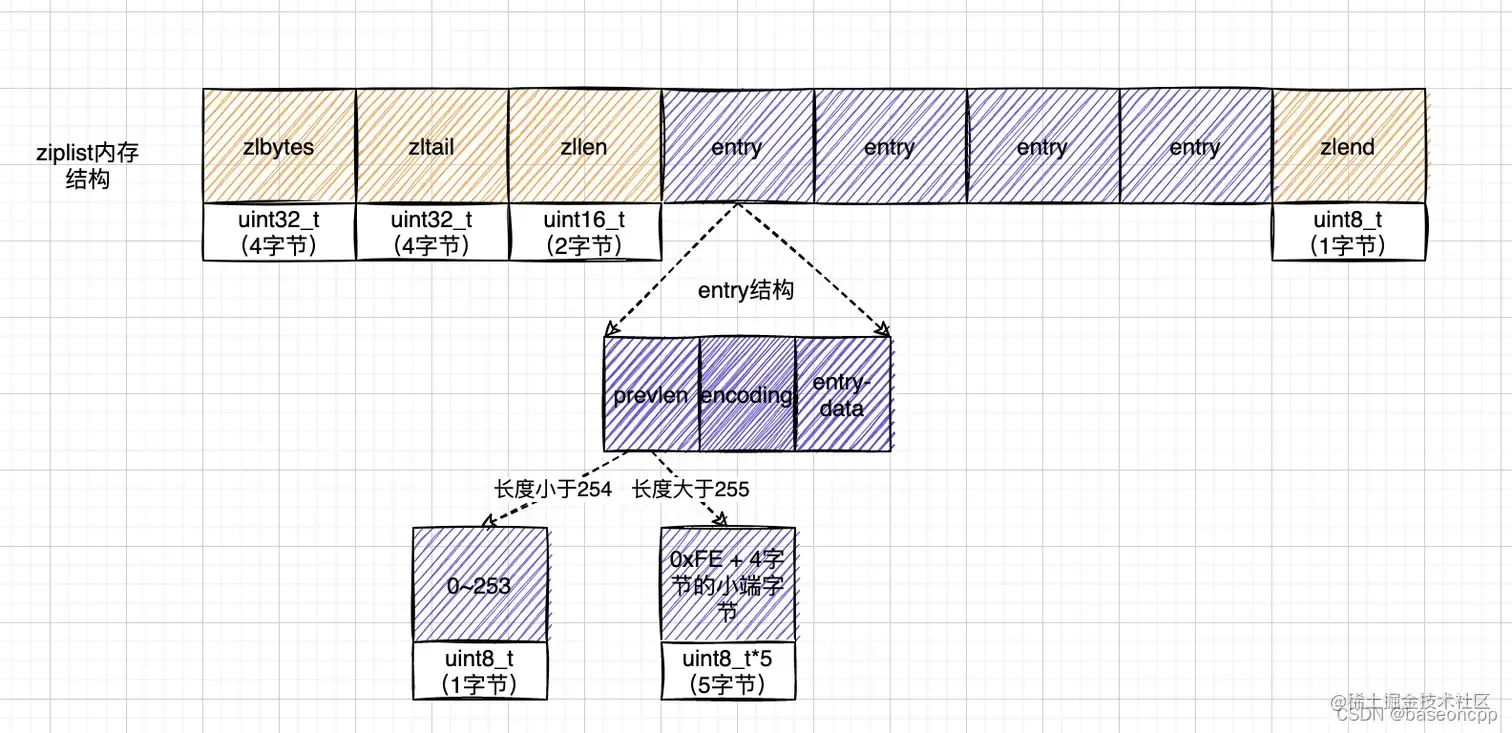
压缩列表(ziplist)本质上就是一个字节数组,是Redis为了节约内存而设计的一种线性数据结构,可以包含任意多个元素,每个元素可以是一个字节数组或一个整数。
展开代码总体结构 <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend> 节点结构 <prevlen> <encoding> <entry-data> 解压后节点结构 typedef struct zlentry { unsigned int prevrawlensize; // 存储prevrawlen需要的字节数 unsigned int prevrawlen; // 前一个节点占用的字节数 unsigned int lensize; // 存储len需要的字节数 unsigned int len; // 数据长度 unsigned int headersize; // 首部长度 = prevrawlensize + lensize unsigned char encoding; // 当前元素编码 unsigned char *p; // 当前元素首地址 } zlentry;
各个字段的含义如下:
- zlbytes:压缩列表的字节长度,占4个字节,因此压缩列表最长(2^32)-1字节;
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节;
- zllen:压缩列表的元素数目,占两个字节;那么当压缩列表的元素数目超过(2^16)-1怎么处理呢?此时通过zllen字段无法获得压缩列表的元素数目,必须遍历整个压缩列表才能获取到元素数目;
- entryX:压缩列表存储的若干个元素,可以为字节数组或者整数;entry的编码结构后面详述;
- zlend:压缩列表的结尾,占一个字节,恒为0xFF。
压缩列表节点分为三个部分:
- previous_entry_length:这个属性记录了压缩列表前一个节点的长度,该属性根据前一个节点的大小不同可以是1个字节或者5个字节。由于压缩列表中的数据以一种不规则的方式进行紧邻,无法通过后退指针来找到上一个元素,而通过保存上一个节点的长度,用当前的地址减去这个长度,就可以很容易的获取到了上一个节点的位置,通过一个一个节点向前回溯,来达到从表尾往表头遍历的操作。
- encoding:encoding通过以下规则来记录content的类型,一字节、两字节或者五字节长, 值的最高位为 00 、 01 或者 10 的是字节数组编码: 这种编码表示节点的 content 属性保存着字节数组, 数组的长度由编码除去最高两位之后的其他位记录;
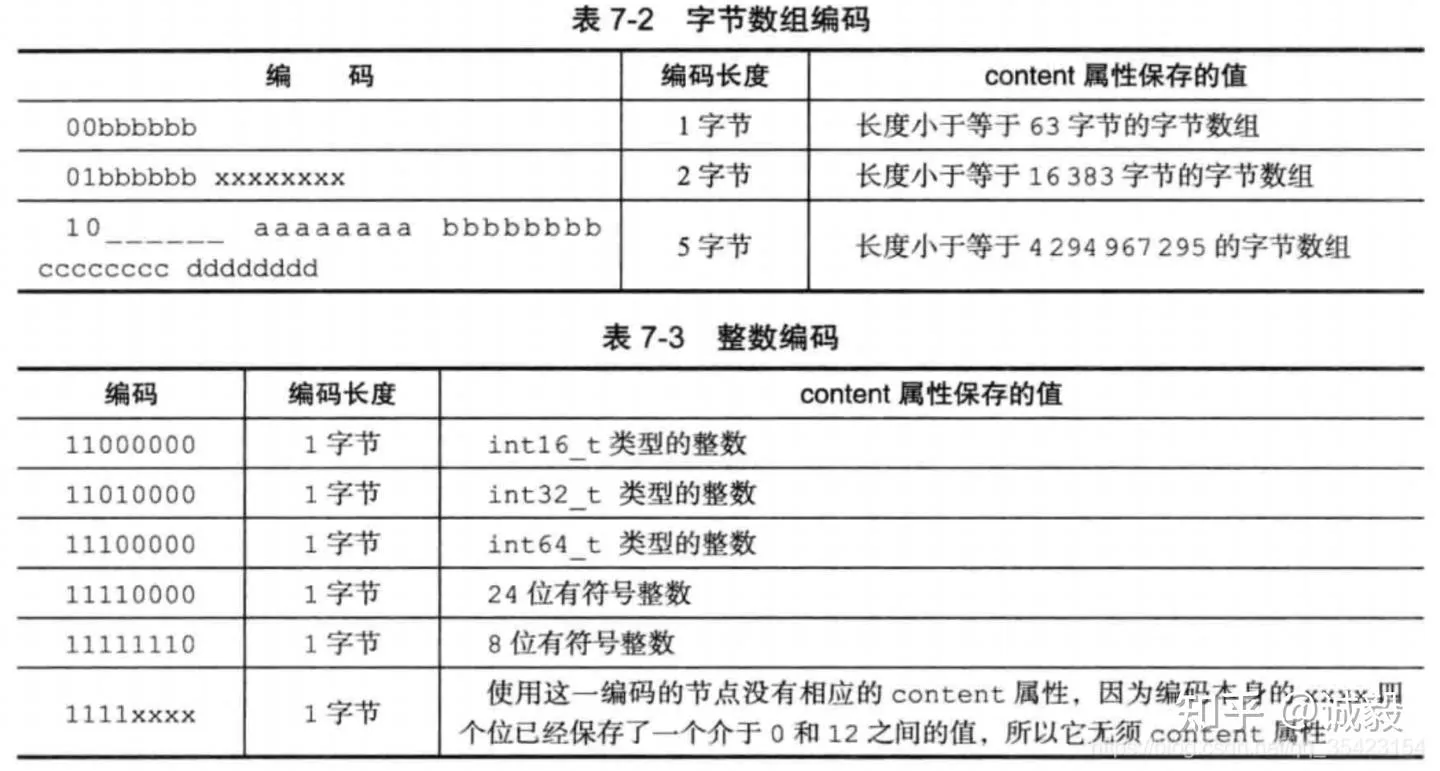 4. content:content属性负责保存节点的值,值的具体类型由上一个字段encoding来决定。
4. content:content属性负责保存节点的值,值的具体类型由上一个字段encoding来决定。
8、listpack
redis7.0,listpack已经完全取代ziplist
listpack作为ziplist的替代者,它的内存布局、实现原理和listpack非常相似。比如:都是连续的一块内存,前端都有表示内存大小、元素个数;尾部都有终结标志等元数据。但是他们彼此之间又有差异。
与ziplist的相同点:
- 头部都用4个字节的无符号整数记录了使用内存的大小;
- 内存块尾部最后一个字节都用来表示列表的终结,而且内容都是0xFF;
- 列表元素(entry)都是根据不同的数据内容编码后存储,条目都包含了三部分内容:编码、长度、数据。
与ziplist的区别:
- 结构组成不同:ziplist内存结构分了四个功能块:ziplist总长度,元素个数,最后元素的偏移和结尾标志;而listpack只有三个功能块:listpack总长度,元素个数和结尾标志,少了最后元素的偏移;
- 数据长度不同:两者的包含元素个数使用的字节长度不一样ziplist是4个字节的uint32_t类型数据,而listpack则是两个字节的unint16_t类型数据,单从这个数据的长度来看,listpack能存储的数据个数是比ziplist少的。因为uint16_t能容纳的数据比uint32_t要少。
- 两者元素结构不同:ziplist元素的三个组成部分分别是:前置元素(entry)的长度数据,本条目的编码方案(包含数据长度)和具体的数据内容;而listpack元素的三个组成部分则是:本条目的编码方案(包含数据长度)、具体的数据内容和本条目前面两个条目数据长度编码后需要的字节数。就是说ziplist条目保存了上一个条目的长度信息,而listpack则保存了自己的长度信息。这两者有很明显的区别,而且这个区别,将影响两者操作的完全不同。.
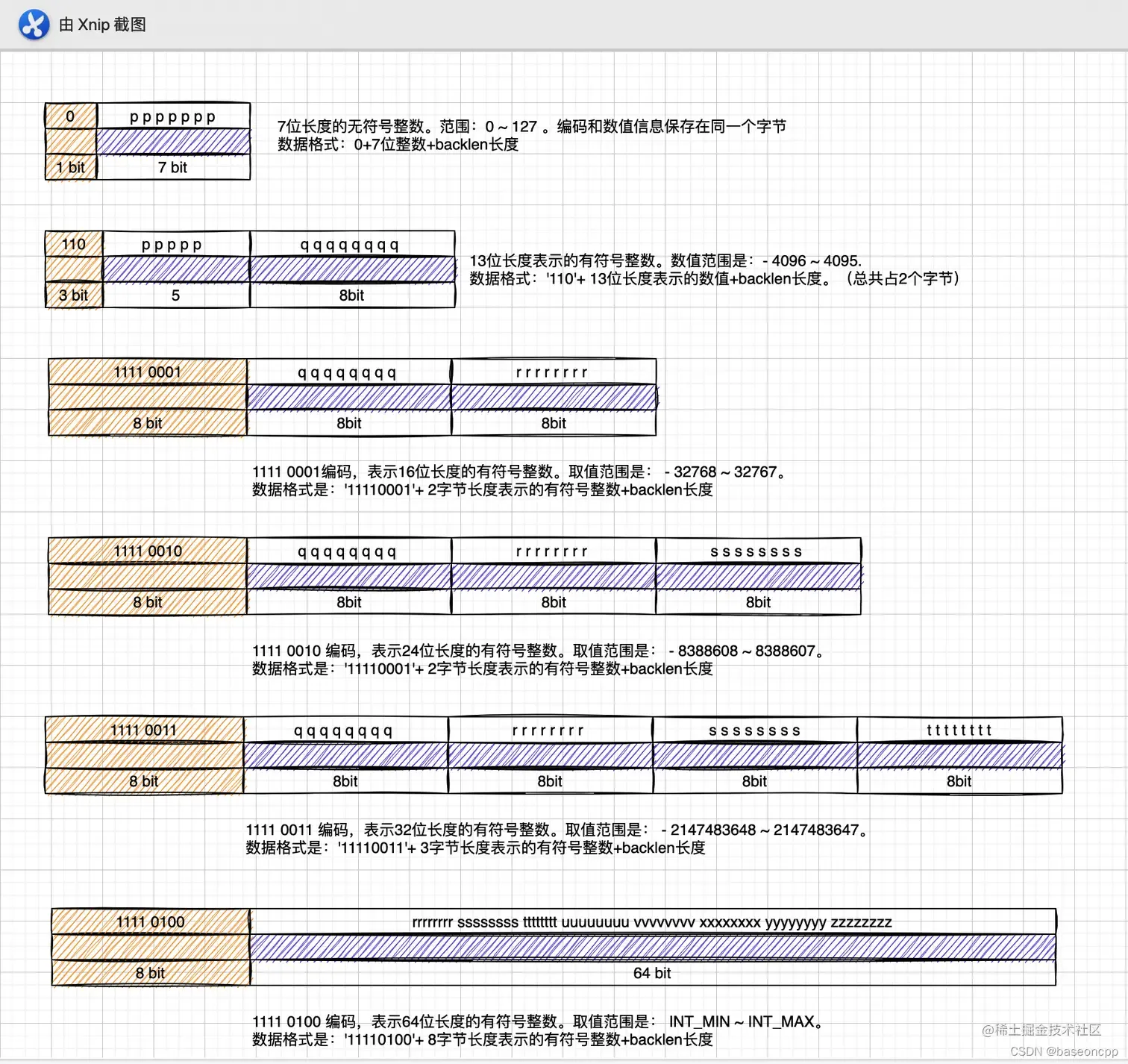
listpack使用1个字节,对其存储的数据制定了11种编码方式。7种用于整数和整数数字组成的字符串编码,内部通过整数的方式压缩存储;3种用户普通字符串数据编码,内部直接使用原字符串的方式进行存储;1种用来表示listpack结束标识的编码。
数字编码主要是用于整数数值和数字组成的字符串。 对于数字组成的字符串,先尝试转换为对应的整数数值,然后根据其大小范围分别采取不同的编码方式和字节长度存储。
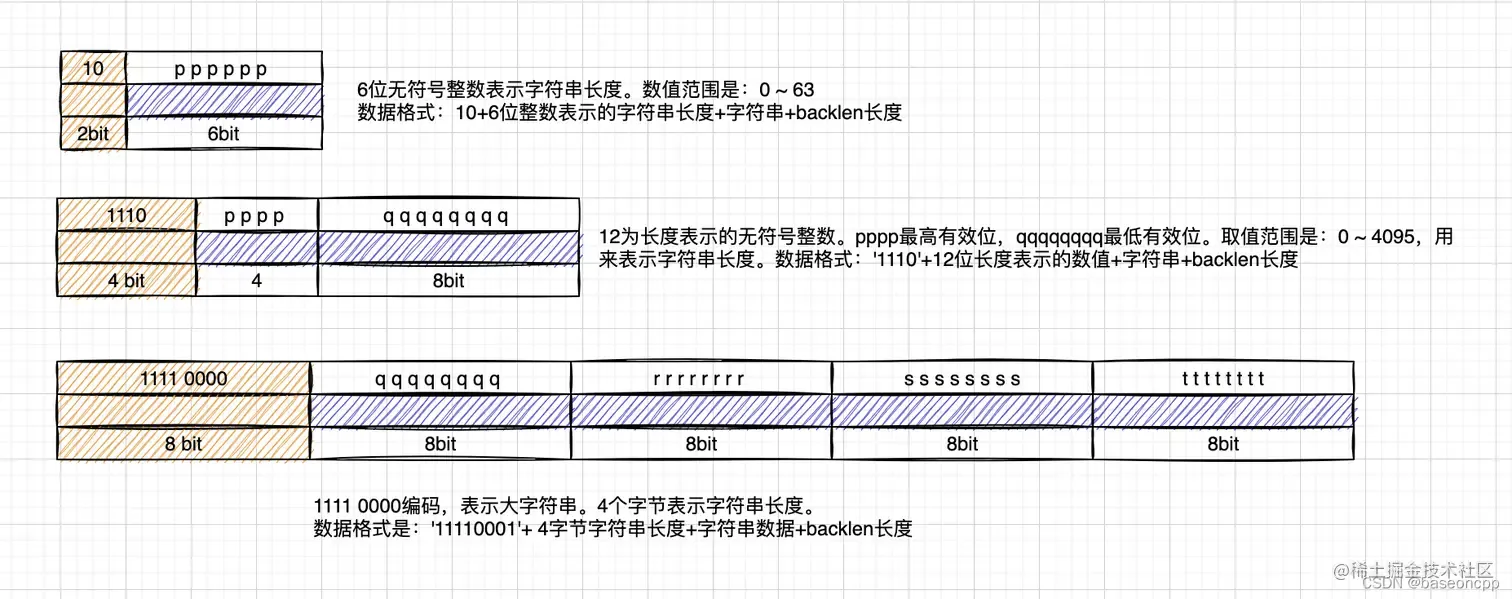
3种字符串编码,分别根据不同的字符串长度,采取不同的编码方式。使用字符串编码的数据,其内容无法通过整数数字压缩编码:包含非数字、不可打印的二进制字符等。以下图片列出了三种字符编码规则:
listpack作为ziplist替代方案。它实现主要目的是底层数据存储,故实现上更偏向空间换时间。对内存空间的使用可以说是“字(节)字较真”,与此同时规定一个listpack最大内存使用不能超过1GB,所以哪怕有部分函数,操作上来看,时间复杂度是0(N),但结合Redis内部对该数据结构的使用方式,其实也在可接受范围内。就比如用作hash底层的实现方案之一,在特定元素数量超过一定数量后,该位hash存储结构。那么数量不多的时候采取listpack作为底层数据存储方案,即使是对其数据进行全量搜索,其耗时也不至于不可接受!
参考文献
本文作者:刘涛
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!