目录
本文带你了解netty架构以及一些线程模型的基础
一、IO模型
IO 是 Input/Output(输入 / 输出) 的缩写,本质是 数据在 “内存” 与 “外部设备” 之间的传输过程。
IO 的核心逻辑
内存是程序运行的核心区域,但数据通常存储在外部设备(如磁盘、网络、键盘、打印机等)中。IO 的目的就是:
- 输入(Input):将外部设备的数据读取到内存(如读文件、接收网络请求);
- 输出(Output):将内存中的数据写入外部设备(如写文件、发送网络响应)。
IO 的关键问题
IO 操作的性能瓶颈往往不在 “数据拷贝” 本身,而在 “等待数据准备”:
- 比如读网络数据时,需要等待网络传输完成(数据到达网卡);
- 读磁盘文件时,需要等待磁盘寻道、旋转(数据加载到内核缓冲区)。
- 这两个步骤(等待数据准备 + 数据拷贝)是所有 IO 模型的核心优化点。
IO 的本质
IO 是 “跨设备的数据搬运”,而 IO 模型就是 “如何高效完成这种搬运” 的设计方案—— 核心解决 “线程在 IO 过程中是否需要阻塞”“如何处理多并发 IO” 的问题。
二、JAVA的IO模型
1、BIO(Blocking IO):同步阻塞 IO
Java 最早的 IO 模型,对应 java.io 包(如 InputStream、OutputStream、Socket),是最直观、最简单的模型。
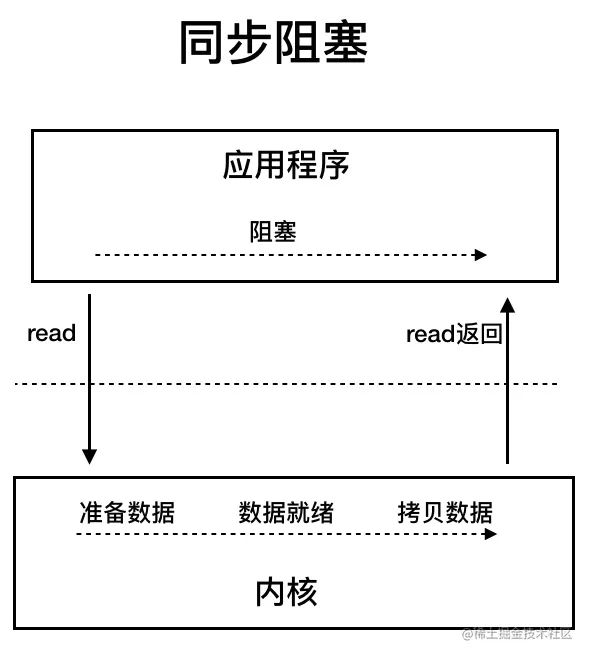
工作原理
- 核心逻辑:一个 IO 操作对应一个线程,线程全程阻塞直到 IO 完成。
- 流程示例(网络通信):
- 服务端启动一个线程,调用 ServerSocket.accept() 阻塞等待客户端连接;
- 客户端连接后,服务端创建新线程处理该客户端的读写(InputStream.read() 会阻塞直到数据到达);
- 客户端断开连接后,线程销毁。
核心特点
- 优点:实现简单,开发成本低,适合调试;
- 缺点:线程开销极大(每个连接对应一个线程),并发能力弱(默认线程池核心线程数有限),适合 连接数少、连接时间长 的场景(如早期的数据库连接)。
2、NIO(Non-blocking IO):同步非阻塞 IO
Java 1.4 引入,对应 java.nio 包(Channel、Buffer、Selector),是解决高并发 IO 的核心模型(Netty 框架的基础)。
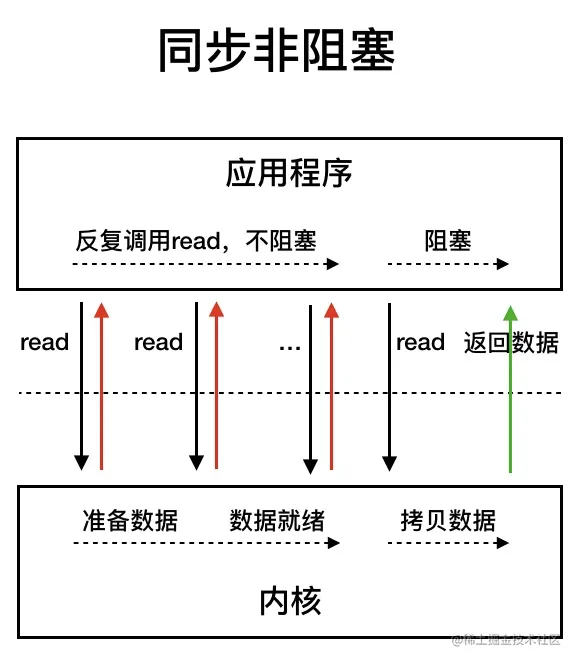
核心组件
- Channel(通道):双向数据通道(替代 BIO 的单向流),支持读 / 写操作,可与 Buffer 交互(如 SocketChannel、FileChannel);
- Buffer(缓冲区):数据存储容器(如 ByteBuffer),IO 操作本质是 “从 Channel 读数据到 Buffer” 或 “从 Buffer 写数据到 Channel”;
- Selector(选择器):核心组件,实现 “多路复用”一个线程通过 Selector 监听多个 Channel 的事件(如 “数据可读”“连接就绪”),仅在 Channel 有事件时才处理。
工作原理
- 核心逻辑:单线程(或少量线程)通过 Selector 管理多个 Channel,线程仅在 Channel 有事件时阻塞(而非全程阻塞)。
- 流程示例(网络通信):
- 服务端创建 Selector 和 ServerSocketChannel,并将 Channel 注册到 Selector(监听 “连接就绪” 事件);
- 调用 selector.select() 阻塞等待事件(无事件时线程休眠,不占用 CPU);
- 客户端连接后,Selector 触发 “连接就绪” 事件,服务端接收连接并注册 SocketChannel 到 Selector(监听 “数据可读” 事件);
- 客户端发送数据后,Selector 触发 “数据可读” 事件,服务端从 Channel 读数据到 Buffer 处理,处理完成后继续等待下一个事件。
核心特点
- 优点:单线程处理多连接,线程开销小,并发能力强(支持万级以上连接),适合 连接数多、连接时间短 的场景(如 HTTP 服务、即时通讯);
- 缺点:实现复杂(需手动管理 Buffer、Selector 事件),开发成本高(Netty 框架简化了 NIO 的编程复杂度)。
IO多路复用
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。
但是,这种 IO 模型同样存在问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
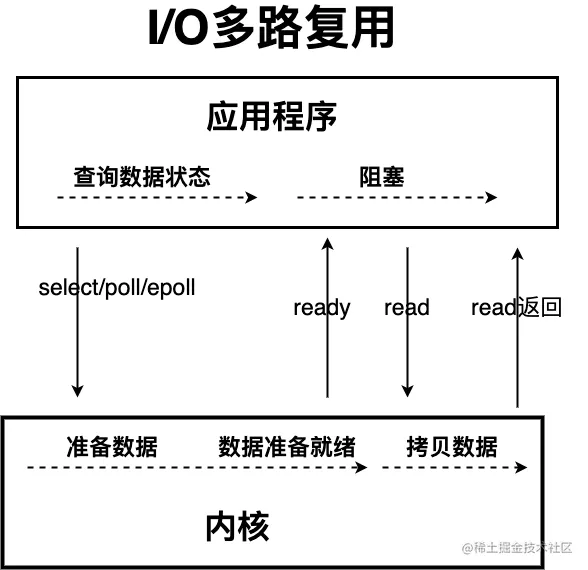
多路复用器Selector
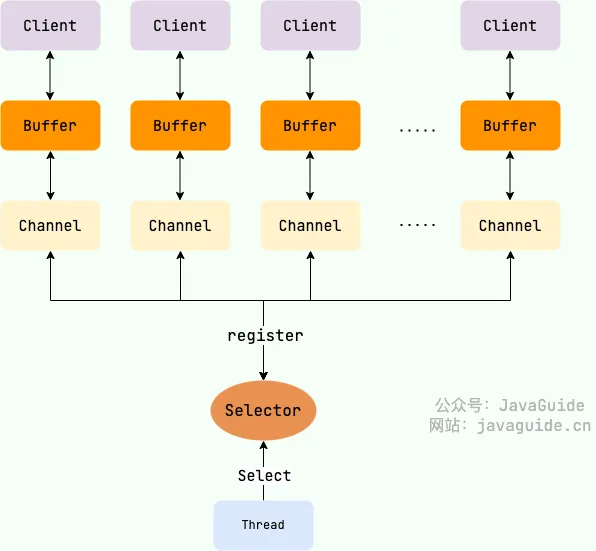
sellect、poll和epoll
目前支持 IO 多路复用的系统调用,有 select,poll和epoll 等等。在介绍这三个概念之前,先科普一些概念:
- 文件描述符(fd):操作系统给每个打开的 IO 资源(网络连接、文件、管道)分配的唯一整数标识,是 IO 操作的核心标识;
- IO 多路复用:一个线程通过系统调用(select/poll/epoll)监听多个 fd,仅当某个 fd 有事件(数据可读、连接就绪)时,才通知应用线程处理;
- 水平触发(LT):fd 有未处理的事件时,系统会持续通知应用(默认模式,select/poll/epoll 均支持);
- 边缘触发(ET):fd 状态从「无事件」变为「有事件」时,系统仅通知一次(仅 epoll 支持,效率更高)。
- 用户态和内核态:权限是核心:用户态 = 低权限(只能操作自己的资源),内核态 = 高权限(能操作系统所有资源);切换是桥梁:用户态程序要访问核心资源,必须通过系统调用切换到内核态,由内核代理执行;性能关联:状态切换有开销,高并发场景(如 IO 密集型服务)需减少无效切换(如用 epoll 替代 select/poll);安全隔离:两种状态的划分避免了用户程序破坏系统,是操作系统稳定运行的基础。
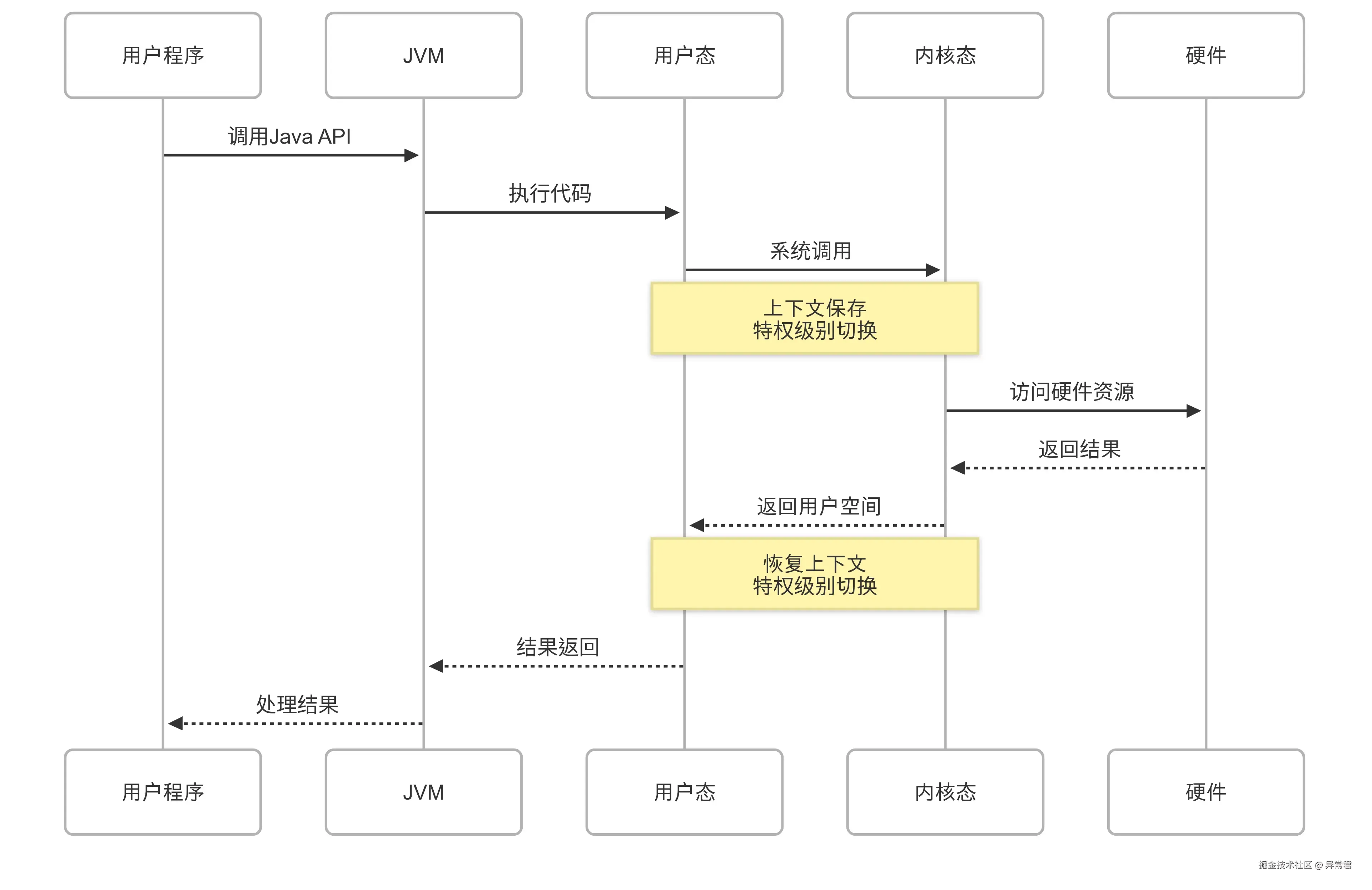
1. select:IO 多路复用的 “初代方案”
- 底层数据结构:位图(bitmask)(本质是固定大小的整数数组,每个 bit 对应一个 fd);
- fd 上限:有硬限制(默认 FD_SETSIZE=1024),即一个 select 最多监听 1024 个 fd(可通过修改内核参数调整,但不推荐,会导致效率下降);
- 核心流程:
- 应用线程将需要监听的 fd 集合(读 / 写 / 异常)拷贝到内核态;
- 内核遍历所有 fd,判断是否有事件就绪;
- 若有事件,内核标记对应的 bit 位,将 fd 集合拷贝回用户态;
- 应用线程遍历整个 fd 集合,找到被标记的就绪 fd 并处理。
- 关键缺点:
- fd 上限硬限制,不适合高并发(超过 1024 个连接就不行);
- 「两次拷贝」:每次调用 select 都要把 fd 集合从用户态拷贝到内核态,处理完再拷贝回来;
- 「无效轮询」:应用线程不知道哪些 fd 就绪,必须遍历整个 fd 集合(哪怕只有 1 个 fd 就绪,也要扫 1024 个),效率随 fd 数增加线性下降。
2、poll:select 的 “小修小补版”
- 底层数据结构:动态数组(struct pollfd)(数组中每个元素存储 fd 和监听的事件类型,无固定大小);
- d 上限:无硬限制(仅受系统内存和内核参数限制),解决了 select 的 fd 上限问题;
- 核心流程:
- 应用线程将 fd 数组(包含 fd 和事件类型)拷贝到内核态;
- 内核遍历数组中所有 fd,判断是否有事件就绪;
- 若有事件,内核修改数组中对应元素的「事件就绪标记」,将数组拷贝回用户态;
- 应用线程遍历整个数组,找到就绪的 fd 并处理。
- 关键改进与缺点:
- 改进:突破 fd 硬限制,支持更多连接;
- 缺点:仍未解决 “两次拷贝” 和 “无效轮询”—— 不管有多少 fd 就绪,内核和应用线程都要遍历所有 fd,效率随 fd 数增加仍会下降(比如 1 万个 fd 中只有 10 个就绪,也要遍历 1 万次)。
3、epoll:IO 多路复用的 “终极优化版”
- (仅 Linux 系统支持,是目前高并发场景的首选,Java 的 Selector 在 Linux 上默认使用 epoll 实现)
- 底层数据结构:红黑树 + 就绪链表:
- 红黑树:存储所有已注册的 fd(支持快速增删查,无 fd 上限);
- 就绪链表:仅存储「有事件就绪」的 fd(无需遍历所有 fd);
- 核心流程(epoll 的三个核心系统调用):
- epoll_create:创建一个 epoll 实例(初始化红黑树和就绪链表);
- epoll_ctl:将需要监听的 fd 注册到 epoll 实例(添加到红黑树),仅注册一次,无需每次拷贝;
- epoll_wait:等待事件就绪 —— 内核监听红黑树中的 fd,若有事件,直接将 fd 加入「就绪链表」;应用线程仅需从就绪链表中取 fd 处理,无需遍历所有注册的 fd。
- 关键优化(解决 select/poll 的所有痛点):
- 无 fd 上限(红黑树支持海量 fd,仅受系统资源限制);
- 「一次注册,永久有效」:fd 注册到 epoll 后,无需每次调用 epoll_wait 都拷贝 fd 集合(仅注册时拷贝一次),解决了 “两次拷贝” 问题;
- 「精准通知」:应用线程直接取「就绪链表」中的 fd,无需遍历所有注册的 fd,解决了 “无效轮询”—— 效率与注册的 fd 总数无关,仅与就绪 fd 数相关;
- 支持「边缘触发(ET)」:仅在 fd 状态变化时通知一次(比如数据从 “无” 到 “有”),减少不必要的通知,进一步提升效率(默认是水平触发 LT)。
3、AIO(Asynchronous IO):异步非阻塞 IO
Java 1.7 引入(NIO.2),对应 java.nio.channels 包下的异步通道(如 AsynchronousSocketChannel),是真正的异步 IO 模型。
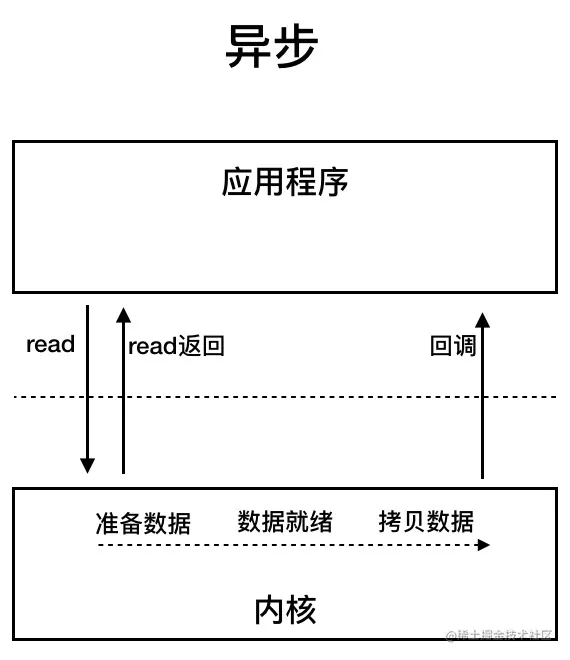
工作原理
- 核心逻辑:线程发起 IO 操作后立即返回,数据准备和拷贝均由操作系统内核完成,内核通过 “回调函数” 或 “Future” 通知应用线程 IO 完成。
- 流程示例(文件读写):
- 线程调用 AsynchronousFileChannel.read() 发起读文件操作,传入回调函数(或 Future 对象),立即返回继续执行其他任务;
- 操作系统内核负责等待文件数据准备,并将数据拷贝到应用内存;
- 拷贝完成后,内核触发回调函数(或设置 Future 状态),应用线程处理结果。
- 核心特点
- 优点:线程完全不参与 IO 操作(无阻塞、无轮询),并发性能最优,适合 IO 操作耗时较长、连接数极多 的场景(如大数据传输、文件服务器);
- 缺点:依赖操作系统内核支持(如 Windows 的 IOCP、Linux 的 epoll 异步模式),实现复杂,兼容性较差(部分 Linux 系统对 AIO 支持不完善),实际应用中不如 NIO 普及(Netty 也未优先支持 AIO)。
4、总结
- IO 的核心是 “内存与外部设备的数据传输”,IO 模型的核心是 “如何优化线程在 IO 过程中的阻塞问题”;
- Java IO 模型的演进是 “BIO → NIO → AIO”,核心目标是 “用更少的线程处理更多的 IO 连接”;
- 实际开发中,NIO 是高并发 IO 的首选(通过 Netty 框架简化开发),AIO 因兼容性和实现复杂度,应用场景相对有限;
- 区分 “同步 / 异步” 看 “数据拷贝是否需要应用线程参与”,区分 “阻塞 / 非阻塞” 看 “线程是否需要等待 IO 完成”。
二、Netty的原理和特点
Netty 是基于 Java NIO 封装的 高性能、高并发网络通信框架,核心目标是解决原生 Java NIO 开发复杂、易出错的问题,同时提供更稳定的高并发支持(默认基于 epoll 多路复用,支持百万级连接)。它广泛应用于 RPC 框架(如 Dubbo)、网关(如 Spring Cloud Gateway)、即时通讯(IM)、消息队列(如 RocketMQ)等场景。
1、Netty的核心原理
Netty 的原理本质是 “对 Java NIO 的优雅封装 + 经典设计模式的应用”,核心围绕「Reactor 线程模型」「事件驱动」「零拷贝」三大核心机制展开。
1.1、核心底层:基于 Java NIO,但解决其痛点
原生 Java NIO 存在三大问题:
- 需手动管理 Buffer、Selector 事件(如空轮询、事件重复触发);
- 线程安全问题(Buffer 非线程安全,需手动同步);
- 网络编程细节繁琐(粘包 / 拆包、断线重连、异常处理)。
Netty 对 NIO 组件做了封装优化:
- Channel:封装 SocketChannel/ServerSocketChannel,提供统一的读写 API(如 writeAndFlush());
- ByteBuf:替代原生 ByteBuffer,支持动态扩容、池化复用、线程安全(通过 Unpooled 或池化缓存减少内存开销);
- Selector:底层自动适配操作系统(Linux 用 epoll、Windows 用 IOCP),解决原生 NIO 的空轮询问题。
1.2、核心设计模式:Reactor 模式(事件驱动)
Netty采用Reactor 线程模型,要理解 Reactor 模式的 单线程、多线程、主从模式,核心前提是:三者均基于事件驱动 + IO 多路复用,差异仅在于 线程的分工与数量配置—— 本质是 “如何拆分连接监听、IO 处理、业务执行的线程责任”,最终目标是解决单线程瓶颈,提升并发能力。
Reactor模式的三种核心角色:
- Reactor(事件分发器):基于 Selector(IO 多路复用器)监听多个 Channel 的事件(连接就绪、数据可读 / 写),并将事件分发给对应的 Handler 处理;
- Handler(事件处理器):负责实际的事件处理:如 “连接建立后的初始化”“数据读写”“业务逻辑执行”(如解码、计算、响应);
- Selector(IO 多路复用器):操作系统提供的组件(如 epoll),用于批量监听多个文件描述符(fd)的事件,避免无效轮询(三种模式共用)。
单线程 Reactor 模式(Reactor Single Thread)
整个 Reactor 模式仅用 1 个线程,该线程同时承担 3 个职责:
- 监听连接:通过 Selector 监听 OP_ACCEPT 事件(客户端连接请求);
- 处理 IO:监听已连接 Channel 的 OP_READ/OP_WRITE 事件(数据读写);
- 执行业务:解码数据、执行业务逻辑、编码响应。
工作流程:
- 单线程启动 Reactor,初始化 Selector 和 ServerSocketChannel(绑定端口),并将 ServerSocketChannel 注册到 Selector(监听 OP_ACCEPT 事件);
- 线程调用 selector.select() 阻塞等待事件;
- 客户端发起连接,Selector 触发 OP_ACCEPT 事件,Reactor 分发事件给「连接 Handler」:接收连接(创建 SocketChannel),并将 SocketChannel 注册到 Selector(监听 OP_READ 事件);
- 客户端发送数据,Selector 触发 OP_READ 事件,Reactor 分发事件给「IO Handler」:从 SocketChannel 读数据 → 解码 → 执行业务逻辑 → 编码响应 → 写回客户端;
- 所有事件处理完毕后,线程回到 selector.select() 继续阻塞等待下一个事件。
优缺点;
- 优点:
- 实现极简,无线程切换开销;
- 无线程安全问题(所有操作在单线程);
- 资源占用少(仅一个线程)。
- 缺点:
- 单线程瓶颈:无法利用多核 CPU,并发能力极弱(支持几百连接);
- 阻塞连锁反应:任何环节阻塞(如业务逻辑耗时、IO 慢),会导致整个系统卡住(所有连接无法处理);
- 可靠性差:线程崩溃,整个服务直接宕机。
Netty实现: Netty 可模拟单线程 Reactor:仅创建一个 EventLoopGroup(含 1 个线程),同时作为 BossGroup 和 WorkerGroup
展开代码EventLoopGroup singleGroup = new NioEventLoopGroup(1); // 单线程 ServerBootstrap bootstrap = new ServerBootstrap() .group(singleGroup, singleGroup) // 主从共用一个线程组 // ... 其他配置
多线程 Reactor 模式(Reactor Multi-Thread)
Reactor 单线程 + Handler 线程池,线程分工拆分:
- Reactor 线程(1 个):仅负责「监听连接」(OP_ACCEPT 事件)和「事件分发」,不处理 IO 和业务;
- Handler 线程池(多个线程):负责「处理 IO」(OP_READ/OP_WRITE)和「执行业务逻辑」,线程池数量通常为 CPU 核心数 × 2。
工作流程:
- 启动 Reactor 线程和 Handler 线程池;
- Reactor 线程初始化 Selector 和 ServerSocketChannel,注册「连接事件」,阻塞等待客户端连接;
- 客户端连接触发 OP_ACCEPT 事件,Reactor 线程接收连接(创建 SocketChannel),并将 SocketChannel 注册到 Handler 线程池中的某个 Selector(轮询分配,负载均衡);
- 客户端发送数据,对应的 Selector 触发 OP_READ 事件,Handler 线程池中的线程读取数据 → 解码 → 执行业务逻辑(耗时操作在多线程中并行) → 编码 → 写回响应;
- Reactor 线程继续阻塞等待下一个连接事件,Handler 线程池循环处理 IO 事件。
优缺点:
- 优点
- 解决单线程瓶颈:IO 和业务逻辑并行处理,充分利用多核 CPU;
- 稳定性提升:单个 Handler 线程阻塞 / 崩溃,不影响其他线程;
- 并发能力显著提升(支持万级连接)。
- 缺点:
- Reactor 线程仍是单线程:连接建立请求过多时(如突发百万连接),Reactor 线程会成为瓶颈;
- 线程切换开销:多线程间上下文切换、数据共享需考虑线程安全(如用线程安全的容器);
- 实现复杂度高于单线程模式。
Netty 中,Reactor 线程对应 BossGroup(1 个线程),Handler 线程池对应 WorkerGroup(多个线程):
展开代码EventLoopGroup bossGroup = new NioEventLoopGroup(1); // Reactor 单线程 EventLoopGroup workerGroup = new NioEventLoopGroup(); // Handler 线程池(默认 CPU*2 线程) ServerBootstrap bootstrap = new ServerBootstrap() .group(bossGroup, workerGroup) // ... 其他配置
主从 Reactor 模式(Master-Slave Reactor)
主 Reactor 线程池 + 从 Reactor 线程池,这是 最高级、最常用 的模式(Netty 默认模式),线程分工彻底拆分:
- 主 Reactor 线程池(BossGroup):仅负责「监听连接」(OP_ACCEPT 事件),接收连接后将 SocketChannel 分发给从 Reactor;线程数默认 1 个(可配置多个,应对高并发连接建立);
- 从 Reactor 线程池(WorkerGroup):每个从 Reactor 绑定一个 Selector,负责「监听 IO 事件」(OP_READ/OP_WRITE),并通过内置线程池处理 IO 和业务逻辑;线程数默认 CPU 核心数 × 2。
工作流程(TCP 服务端,Netty 实际流程):
- 启动主 Reactor 线程池(BossGroup)和从 Reactor 线程池(WorkerGroup);
- 主 Reactor 线程初始化 Selector 和 ServerSocketChannel,注册「连接事件」,阻塞等待客户端连接;
- 客户端连接触发 OP_ACCEPT 事件,主 Reactor 线程接收连接(创建 SocketChannel),并通过「负载均衡」将 SocketChannel 注册到从 Reactor 线程池的某个 Selector 上(监听 OP_READ 事件);
- 客户端发送数据,对应的从 Reactor 线程的 Selector 触发 OP_READ 事件,从 Reactor 线程读取数据 → 解码 → 执行业务逻辑 → 编码 → 写回响应;
- 主 Reactor 继续接收新连接,从 Reactor 继续处理已有连接的 IO 事件,两者并行工作,互不干扰。
关键优化点:
- 「连接建立」和「IO 处理」完全分离:主 Reactor 只负责 “接客”,从 Reactor 只负责 “服务”,两个环节都支持多线程并行,无瓶颈;
- 从 Reactor 线程池的每个线程绑定独立 Selector:避免单个 Selector 监听过多 Channel 导致的事件分发延迟;
- 支持动态扩容:主 / 从 Reactor 线程数可根据业务需求配置(如 BossGroup 配置 2 个线程,应对突发连接峰值)。
Netty 的默认配置就是主从 Reactor 模式,直接使用即可:
展开代码// 主 Reactor 线程池(BossGroup):默认 1 个线程,可指定线程数(如 new NioEventLoopGroup(2)) EventLoopGroup bossGroup = new NioEventLoopGroup(); // 从 Reactor 线程池(WorkerGroup):默认 CPU 核心数 × 2 个线程 EventLoopGroup workerGroup = new NioEventLoopGroup(); ServerBootstrap bootstrap = new ServerBootstrap() .group(bossGroup, workerGroup) // 绑定主从线程池 .channel(NioServerSocketChannel.class) // ... 其他配置(编解码器、Handler 等)
1.3、关键优化:零拷贝(Zero-Copy)
Netty 的「零拷贝(Zero-Copy)」并非字面意义上的 “完全无数据拷贝”,而是 通过一系列优化减少「用户态与内核态之间的无效数据拷贝」和「应用层内的不必要内存拷贝」,核心目标是降低内存开销、减少 GC 压力、提升 IO 吞吐量 —— 这也是 Netty 高性能的核心原因之一。
要理解 Netty 的零拷贝,首先要明确:零拷贝的核心是 “避免数据在不同内存区域(如内核缓冲区、用户缓冲区、JVM 堆)之间的重复拷贝”,尤其是 “用户态 ↔ 内核态” 的拷贝(CPU 开销大、耗时久)。
传统 IO 的拷贝痛点(为什么需要零拷贝?)
在讲解 Netty 零拷贝前,先看传统 IO(如 Java 原生 InputStream/OutputStream)的文件传输流程,理解其拷贝冗余。传统 IO 传输文件的流程(以 “读文件并发送到网络” 为例):
硬盘 → 内核缓冲区(DMA 拷贝)→ 用户缓冲区(JVM 堆,CPU 拷贝)→ Socket 缓冲区(CPU 拷贝)→ 网卡
- 3 次数据拷贝:硬盘→内核(DMA 无 CPU 参与)、内核→用户堆(CPU 拷贝)、用户堆→Socket 缓冲区(CPU 拷贝);
- 2 次状态切换:用户态→内核态(读文件)、内核态→用户态(写网络);
- 核心问题:两次 CPU 拷贝完全是无效冗余(数据只是从内核到用户堆 “过一手”,没有任何业务处理),且状态切换和拷贝开销随数据量增大而急剧上升。
Netty 零拷贝的 5 大核心实现(从底层到应用层)
Netty 的零拷贝是「多层优化的组合」,涵盖 操作系统层面的内核级优化 和 应用层面的封装优化,以下按 “优先级 + 常用程度” 逐一拆解:
1. 核心优化:基于操作系统的 transferTo/transferFrom(内核级零拷贝)
这是 Netty 中最经典的零拷贝技术,依赖操作系统提供的 sendfile() 系统调用(Linux)或 TransmitFile()(Windows),实现「内核态内部的数据直接拷贝」,完全跳过用户态。
- 核心思想:让数据在「内核缓冲区」和「Socket 缓冲区」之间直接拷贝(由操作系统内核完成,无需 CPU 参与,或仅少量参与),跳过「用户缓冲区(JVM 堆)」这一中间环节;
- Netty 封装:通过 FileRegion 类封装这一逻辑,底层调用 FileChannel.transferTo() 或 FileChannel.transferFrom() 系统调用。
关键优化点:
- 拷贝次数从 3 次减少到 2 次,且消除了两次 CPU 拷贝(仅保留 DMA 拷贝,DMA 是硬件直接操作内存,不占用 CPU);
- 状态切换从 2 次减少到 1 次(仅发起 transferTo() 时的一次用户态→内核态切换,内核完成所有拷贝后直接返回);
- 适用场景:大文件传输、文件服务器、静态资源服务(如 Nginx 底层也用类似技术)。
2、应用层优化:CompositeByteBuf(复合缓冲区,避免合并拷贝)
传统 IO 中,若需要合并多个缓冲区(如 TCP 粘包拆包时,将多个分片数据合并为完整消息),必须创建新缓冲区,将所有数据拷贝进去 —— 这是典型的 “应用层无效拷贝”。Netty 的 CompositeByteBuf 解决了这一问题:通过维护多个子 ByteBuf 的引用,模拟一个 “统一的缓冲区”,无需拷贝子缓冲区的数据。
- CompositeByteBuf 内部维护一个 ByteBuf 数组,所有子 ByteBuf 共享底层内存,不进行数据拷贝;
- 对外提供统一的读写 API(如 readByte()、writeBytes()),上层业务无需关心数据分散在多个子缓冲区中。
适用场景:
- TCP 粘包 / 拆包(如 HTTP 协议的请求头和请求体分离,合并时无需拷贝);
- 自定义协议中,消息由多个字段 / 分片组成(如长度字段 + 数据字段)。
3. 内存优化:DirectByteBuf(直接缓冲区,跳过 JVM 堆拷贝)
Java 原生 ByteBuffer 分为「堆缓冲区(HeapByteBuffer)」和「直接缓冲区(DirectByteBuffer)」:
- 堆缓冲区:数据存储在 JVM 堆中,IO 操作时需先拷贝到内核缓冲区(用户态→内核态拷贝);
- 直接缓冲区:数据存储在「堆外内存(Off-Heap Memory)」,直接映射到操作系统内核缓冲区,IO 操作时无需拷贝(内核可直接访问堆外内存)。
Netty 封装了 DirectByteBuf(直接缓冲区),并通过「池化技术」解决了直接缓冲区 “分配 / 回收开销大” 的问题,成为高并发 IO 的首选。
4. 对象复用:ByteBuf 池化(减少内存分配与 GC)
原生 Java ByteBuffer 是 “一次性对象”:每次 IO 操作都要创建新对象,使用后被 GC 回收 —— 频繁的创建 / 回收会导致 GC 频繁(STW 时间长),影响系统稳定性。 Netty 的「ByteBuf 池化」是另一种 “零拷贝” 思路:通过复用 ByteBuf 对象,避免频繁内存分配和回收,减少 GC 压力(本质是 “避免因对象创建导致的间接拷贝和开销”)。
原理:
- Netty 提供 PooledByteBufAllocator(默认分配器),维护一个 ByteBuf 对象池(分为堆缓冲区池和直接缓冲区池);
- 当需要 ByteBuf 时,从池中获取(而非新建);使用完毕后,归还给池(而非释放给 GC);
- 池化策略:基于线程本地缓存(ThreadLocal)和内存页(Page)管理,支持快速分配和回收。
5. 底层优化:Unsafe 直接内存操作
Java 的 Unsafe 类提供了直接操作内存地址的底层 API(绕过 Java 安全模型),Netty 基于 Unsafe 实现了 ByteBuf 的读写逻辑,避免了 Java 层面的额外拷贝和封装开销。
原理:
- Unsafe 可直接访问内存地址(如 getByte(long address)、putByte(long address, byte value)),无需经过 Java 对象的字段访问逻辑;
- Netty 的 AbstractUnsafeByteBuf 子类(如 PooledDirectByteBuf)基于 Unsafe 实现,读写效率比 Java 原生 ByteBuffer 高 30% 以上。
Netty 的零拷贝技术是其高性能的核心支柱之一,核心逻辑是「从内核到应用层,层层减少无效拷贝和冗余开销」:
- 内核级:用 transferTo 消除用户态与内核态的拷贝;
- 应用层:用 CompositeByteBuf 避免缓冲区合并拷贝;
- 内存层:用 DirectByteBuf 跳过 JVM 堆拷贝,用池化减少 GC;
- 底层:用 Unsafe 优化读写效率。
1.4、事件驱动:ChannelPipeline 与 ChannelHandler
Netty 是「事件驱动」框架,所有 IO 操作(连接建立、数据读写、异常关闭)都会被封装为「事件」,通过 ChannelPipeline(事件流水线)传递给 ChannelHandler(事件处理器)处理。
- ChannelPipeline:维护一个 ChannelHandler 链表,事件按顺序传递(入站事件从头部到尾部,出站事件从尾部到头部);
- ChannelHandler:核心业务处理组件,分两类:
- 入站处理器(ChannelInboundHandler):处理读事件、连接建立事件(如 SimpleChannelInboundHandler);
- 出站处理器(ChannelOutboundHandler):处理写事件、连接关闭事件(如 ChannelOutboundHandlerAdapter);
- 编解码器:本质是 ChannelHandler,用于处理 TCP 粘包 / 拆包(如 LengthFieldBasedFrameDecoder 按长度拆包、StringDecoder 字符串解码)。
三、基于上述原理,Netty 具备以下核心优势
高性能:
- 基于 epoll 多路复用,支持百万级并发连接;
- 零拷贝优化 + ByteBuf 池化,减少内存开销和 GC 压力;
- 主从 Reactor 模型,充分利用多核 CPU,避免单线程瓶颈。
易用性:
- 封装原生 NIO 的复杂细节(如 Selector 事件处理、Buffer 管理);
- 提供丰富的开箱即用组件(编解码器、断线重连、心跳检测、SSL 加密);
- 简洁的 API 设计(如 Bootstrap 快速启动服务端 / 客户端)。
稳定性:
- 解决原生 NIO 的空轮询、事件泄露等 Bug;
- 完善的异常处理机制(如 exceptionCaught() 统一捕获异常);
- 支持连接超时、心跳检测,避免无效连接占用资源。
扩展性:
- 基于 ChannelHandler 组件化设计,可按需组合(如添加日志、监控、加密处理器);
- 支持自定义编解码器(适配 Protobuf、JSON 等自定义协议);
- 可灵活配置线程池参数(如 BossGroup 线程数、WorkerGroup 线程数)。
跨平台:
底层自动适配不同操作系统的 IO 模型(Linux epoll、Windows IOCP、BSD kqueue),开发无需关注底层差异。
参考;
本文作者:刘涛
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!